
Modele danych to podstawa programowania. Jak wyglądałyby nasze programy bez danych? W większości przypadków (o ile nie we wszystkich) nie miałyby one sensu. Rzemiosło dobrego programowania nie jest łatwe – wymaga dyscypliny, koncentracji i wiedzy. Z tą ostatnią bywa różnie… Dzisiejszy wpis będzie poświęcony dwom wzorcom modelowania danych – modelowi anemicznemu i bogatemu.
Cześć 

Na przełomie czasów została rozwiązana już masa problemów z wykorzystaniem przeróżnych rozwiązań – jedne się sprawdziły, inne niekoniecznie. Problemy z jakimi stawiamy się jako programiści w teraźniejszości prawdopodobnie zostały już przepracowane przez kogoś innego. Myślę, że w 90% to co wyróżnia nasze programy to biznes i koncepcja za nim stojąca. Jednak jeżeli się zastanowimy to może się okazać, że każdy z tych biznesów ma coś wspólnego. Większość z rozwiązywanych problemów u swoich podstaw jest podobna… Taka mysł na start, która z tym artykułem ma trochę wspólnego ale na ten temat można śmiało poświęcić cały osobny wpis.
A teraz nie przedłużając dalej. W dzisiejszym artykule:
Czym jest model anemiczny?
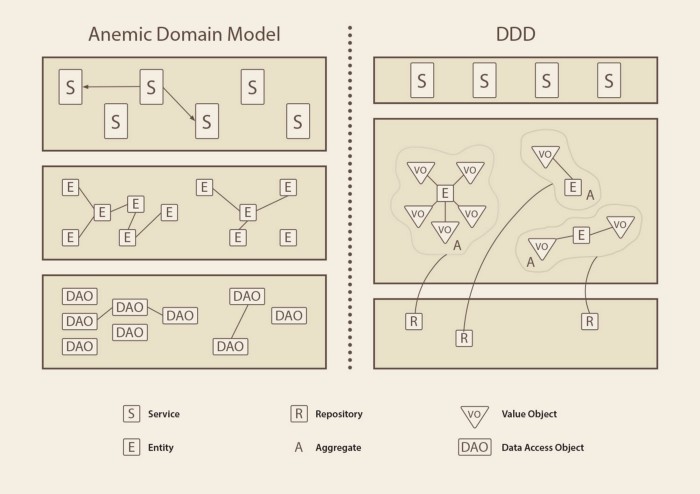
Model anemiczny to nic innego jak model posiadający dane (pola/atrybuty) oraz połączenia do innych modeli (referencje). Taki model będzie też posiadał zestaw getterów i setterów. Logika biznesowa takiego modelu jest używana przez różnego rodzaju serwisy, utilsy i inne manager’y. To one definiują zachowania i reguły.
Będąc w projektach komercyjnych od ponad 2 lat spotykałem się głównie z takim podejściem. Mogę przez to wnioskować, że jest ono nadużywane. Dlaczego tak się dzieje? Do głowy przychodzą mi trzy powody.
- Jeden – wiele tutoriali zostało napisanych właśnie w taki sposób. Twórcy popularnych frameworków sugerują nam takie rozwiązania, poprzez przedstawianie nam poradników jak używać ich frameworków w szybki sposób.
- Dwa – nie zastanawiamy się nad tym do czego dany model jest potrzebny, jaki problem ma rozwiązywać. PO mówi: feature będzie służył do rezerwacji hoteli, tutaj masz schemat bazy, wiesz jak to będzie wyglądać i działajmy. I później szybko klepiemy schemat bazy 1:1 z obiektami. A po miesiącu dochodzą nowe funkcjonalności, które – uwaga – opędzlowujemy przez nowe serwisy. I tak do momentu aż projekt umiera i piszemy go od nowa. Brzmi znajomo?
- Trzy – jest prosty w użyciu. Super prezentacja z Confitury z 2013 roku omawiająca ten problem : Encja na twarz i pchasz.
- Cztery – nie mamy umiejętności. Powód jeden i dwa bardzo temu sprzyjają. Nie mamy czasu się nauczyć programować inaczej. Jeżeli obracamy się w środowisku, gdzie wszyscy pracują w taki sam sposób to być może nigdy nie będziemy mieli tego czasu na naukę. Smutna prawda.
W roku 2003 Martin Fowler zdefiniował model anemiczny jako anty wzorzec. Zwraca on szczególną uwagę na brak spójności takiego podejścia z programowaniem obiektowym a nawet zarzuca, że jest to proceduralny styl projektowania.
The anemic domain model is really just a procedural style design…
Jedną z fundamentalnych podstaw programowania obiektowego jest enkapsulacja. Co to oznacza? Nasze dane powinny być ukrywane. A my co robimy?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | public class User { private String name; private String idNum; public String getName() { return name; } public String getIdNum() { return idNum; } public void setName(String newName) { name = newName; } public void setIdNum(String newId) { idNum = newId; } } |
Na początku naszych 'karier’ wmawia się nam, że enkapsulacja to ukrywanie pól i używanie akcesorów do nich. Błąd! Enkapsulacja polega na ukrywaniu danych! Tylko jeżeli ukryjesz dane modelu i nie zdefiniujesz w nim zachowań to w jaki sposób chcesz zmieniać jego stan?
Czym jest model bogaty?
Model bogaty, w przeciwieństwie do anemicznego, poza samymi danymi definiuje również logikę domenową. Dane i zachowania są spójne. Zachowania są częścią i rezultatem modelu. Logika jest odpowiedzialna za inicjalizację obiektów, walidację i operowanie na modelu.
Dzięki takiemu podejściu klient danej domeny nie musi się martwić którego serwisu musi użyć. Albo czy zmieniając dane w jednym serwisie nie zepsuje logiki w innym. Wszystkie zmiany danych związane z obiektem są zdefiniowane właśnie w nim. Pozwala to kontrolować stan obiektu, dzięki czemu unikamy stanu niespójności.
Nie oznacza to, że całkowicie pozbywamy się serwisów. One nadal są – tylko służą nam do innych celów, np. wysyłanie maili. Cytat z książki DDD Erica Evans’a:
This layer is kept thin. It does not contain business rules or knowledge, but only coordinates tasks and delegates work to collaborations of domain objects in the next layer down. It does not have state reflecting the business situation, but it can have state that reflects the progress of a task for the user or the program.
Nie będę w tym artykule się zagłębiał w podejście DDD, czym są agregaty, value objecty, itd. Przedstawię Ci natomiast prosty model subskrypcji, który jest implementacją modelu bogatego. Zachowania są definiowane razem z danymi i są ściśle powiązane z obiektem.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | public class Subscription { private Status status = Activated; private final Clock clock; private final SubscriptionId subscriptionId; private final Enrollment enrollment; public static Subscription subscription(int maxSubscribers, int maxOnWaitingList) { return new Subscription(systemDefaultZone(), Enrollment.emptyWithCapacities(maxSubscribers, maxOnWaitingList), SubscriptionId.newOne()); } public static Subscription subscription(int maxSubscribers, int maxOnWaitingList, SubscriptionId subscriptionId) { return new Subscription(systemDefaultZone(), Enrollment.emptyWithCapacities(maxSubscribers, maxOnWaitingList), subscriptionId); } Subscription(Clock clock, Enrollment enrollment, SubscriptionId subscriptionId) { this.clock = clock; this.enrollment = enrollment; this.subscriptionId = subscriptionId; } enum Status { Activated, Disabled } Result activate() { this.status = Activated; return success(new SubscriptionActivated(subscriptionId, Instant.now(clock))); } Result disable() { this.status = Disabled; return Result.success(new SubscriptionDisabled(subscriptionId, Instant.now(clock))); } } |
Zero niepotrzebnych udostępnień danych. Wszystko wykonywane jest przez zdefiniowane zachowania. W tym przypadku klasa subskrypcji ma dwa bardzo proste zachowanie – może być aktywna lub nieaktywna. I tyle.
Oczywiście nie może być tak kolorowo, musisz zapłacić cenę za to aby Twój design szedł w taką stronę. Ceną jest czas i umiejętność komunikacji. My (developerzy) dostarczamy rozwiązania biznesom, które mają na tym zarobić. Oni wiedzą w jaki sposób ma działać ich biznes (ich domena). A my? No już nie koniecznie. Naszym zadaniem jest zdobyć tą wiedzę. Dopytywać, dociekać i dopiero wtedy projektować. Na youtubie możesz obejrzeć świetną prezentację Sławka Sobótki, która pokazuje taki proces event stormingu.
Co jest lepsze?
Trochę 'clickbaitowo’ rzuciłem hasło co jest lepsze. Oczywiście to zależy.
Jeżeli piszesz CRUD’a, gdzie nie ma żadnej walidacji, żadnej logiki lub jest ale jest jej mało, to nie ma co się rozwodzić. Używasz modelu anemicznego i wykorzystujesz powiedzenie encja na twarz i pchasz.
Natomiast kiedy widzisz, że logika w domenie w jakiej pracujesz staje się skomplikowana, użyj modelu bogatego. Co to znaczy skomplikowana? Powstają nowe walidacje, zmieniają się stare reguły, dochodzą nowe – generalnie – jest dużo zmienności.
Podsumowanie

Model anemiczny możesz tłumaczyć jako:
- posiadający wyłącznie dane, nie posiadający prawie żadnej logiki.
- serwisy zarządzają atrubytami takiego modelu poprzez akcesory i to one definiują logikę aplikacji
- dane są oddzielone od reguł (zarządzają nimi serwisy)
Model bogaty natomiast:
- logika jest zaimplementowana w obiektach modeli
- serwisy stanowią jedynie cienką wartstwę wspomagającą serwisy trzecie (np. zapis do bazy, koordynacja zadań)
- dane są dostępne tylko przez reguły (reguły to zachowania domenowe)
Źródła:
- Domain-Driven Design vs. anemic model. How do they differ?
- AnemicDomainModel
- Anaemic Domain Model vs. Rich Domain Model
- The Anaemic Domain Model is no Anti-Pattern, it’s a SOLID design
- Anemic Domain Model vs Rich Domain Model with Examples
Za tydzień
Porozmawiamy o czasie w Javie. Co używać, jak używać i jakie są konekwencje.
Bardzo fajny artukuł, dzieki! Szkoda tylko, że RDM jest tak bagatelizowany, programuje od kilku lat i w każdym projekcie sytuacja była podobna, klasa posiada pola, gettery i settery a logika biznesowa roproszona po różnych klasach typu service, helper itd.
Cześć, Rich Domain Model to czyste zło! Po pierwsze w RDM metody, które operują na danym obiekcie znajdują się wewnątrz tego obiektu. Powoduje to, że juniorom, bądź nowym członkom projektu łatwiej znaleźć zaimplementowane już funkcje (ponieważ są zdefiniowane w jednym miejscu). Jest to bardzo niekorzystne zjawisko, ponieważ wiadomo, że nowi programiści powinni najpierw przeiterować po całej warstwie serwisów (w większych projektach są to nawet setki klas) żeby sprawdzić, czy funkcjonalność, której akurat potrzeba nie została już zaimplementowana wcześniej. Najczęściej jednak źli programiści, nie wiedzieć czemu (może dziwnie implementować 1 mały ficzer przez tydzień?), nie chcą ogarnąć kodu całej aplikacji, żeby zrobić… Czytaj więcej »
Niestety, ale z biegiem czasu co raz bardziej się przekonuję, że jest tak jak piszesz. Oczywiście zmiany zaczynają się od nas – więc jak chcemy coś zmienić to musimy wychodzić z inicjatywą. Pytanie tylko czy warto.
Bardzo dobry wpis, gratulacje! Chciałbym dodać od siebie że model „anemiczny” vs domenowy to fałszywa dychotomia. Istnieje wiele podejść pomiędzy, np. jednym z moich ulubionych jest podejście promowane przez Jimmiego Bogarta (https://jimmybogard.com/) będące w duzym uproszczeniu połączeniem CQS (Command query separation – nie mylić z CQRS) z modelem anemicznym. Cechy szczególne tego podejścia to podział serwisów na command i query handlery. Uzycie wzorca mediator do wywolania odpowiedniego command handlera gdy posiadamy obiekt komendy. Uzycie event publishera i event handlerow do obslugi efektow „pobocznych”. Operowanie bezposredion na encjach w command handlerach. I na koniec testowanie głównie na poziomie command handlerów (niektórzy… Czytaj więcej »
Hej, po pierwsze, dzięki za komentarz.
Sprawdzę na czym polega to podejście, które promuje Jimmy.
Wydaje się, że ta prezentacja z 2018 będzie do tego dobrym wstępem.
A prezentację o której wspomniałeś na konferencji BuildStuff w Wilnie można znaleźć tutaj (zgaduję na 99%, że to jest to).