
Czy potrzebujesz akcesorów (getterów i setterów), żeby móc zapisywać i odczytywać modele w Hibernate? Takie pytanie dostałem na jednej z rozmów kwalifikacyjnych… i przyznam szczerze – nie znałem na nie odpowiedzi. Nie miałem pojęcia jak działa Hibernate pod spodem.
darmowy dostęp do danych nie przekłada się na wiedzę jeżeli nie włożymy w to nieco wysiłku.
Hans Rosling, Factfulness. Dlaczego świat jest lepszy, niż myślimy, czyli jak stereotypy zastąpić realną wiedzą
Cześć 

Hibernate jest wiodącym narzędziem do konwertowania danych z bazy do obiektów Javowych i odwrotnie, czyli tak zwanym ORM’em. Mimo, że w ponad 90% aplikacji, które posiadają kontakt z bazą relacyjną wykorzystywany jest Hibernate, to nadal nie mamy świadomości co się dzieje pod spodem.
No dobra… wiemy, że nie musimy pisać sql’ek, które skutecznie wyciągną lub wsadzą coś do bazy. Tematów związanych z Hibernate’m, na których temat można pisać posty jest dużo ale dziś skupimy się na definiowaniu strategi dostępu – albo bardziej jak to działa w Hibernacie.
W dzisiejszym artykule:
Field vs Property Access
Hibernate – zgodnie ze standardem JPA – oferuje dwa sposoby dostępu do manipulowania obiektem zarządzanym (takim, który posiada adnotację @Entity). Możemy użyć Field-based access lub Property-based access.
Obydwie metody nie wymagają od developera dużego nakładu sił – wystarczy dodać odpowiednią adnotację w klasie którą oddajemy we władanie frameworkowi. W obu przypadkach adnotacja będzie taka sama – @Id. Jaka jest więc różnica?
Field-based access oznacza, że nasze adnotacje znajdują się bezpośrednio nad polami w klasie. Hibernate używa refleksji do odczytu i zapisu danych.
1 2 3 4 5 6 7 8 9 10 11 12 | @Entity(name = "Book") public static class Book { @Id private Long id; private String title; private String author; //Getters and setters are omitted for brevity } |
Property-based access natomiast wykorzystuje akcesory (gettery i settery) do dostępu do atrybutów klasy a adnotacje umieszczamy nad getterami atrybutów.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | @Entity(name = "Book") public static class Book { private Long id; private String title; private String author; @Id public Long getId() { return id; } public void setId(Long id) { this.id = id; } public String getTitle() { return title; } public void setTitle(String title) { this.title = title; } public String getAuthor() { return author; } public void setAuthor(String author) { this.author = author; } } |
Definiowanie Strategi
Domyślnie strategia jest definiowana na zasadzie – tam gdzie jest adnotacja @Id, taki rodzaj dostępu wybierz. Czyli jeżeli adnotację @Id umieszczasz bezpośrednio nad polem to Hibernate (a w zasadzie to standard JPA) wybierze Field-based access i analogicznie jeżeli umieścisz adnotację nad getterem to zostanie wybrany Property-based access.
W specyfikacji JPA 2.0 pojawiła się nowa adnotacja @Access, która umożliwia łączenie obu technik.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | @Entity(name = "Book") public static class Book { private Long id; private String title; private String author; @Access( AccessType.FIELD ) @Version private int version; @Id public Long getId() { return id; } public void setId(Long id) { this.id = id; } public String getTitle() { return title; } public void setTitle(String title) { this.title = title; } public String getAuthor() { return author; } public void setAuthor(String author) { this.author = author; } } |
Wydajność – co będzie lepsze?

W kwestii wydajności można by było bazować na tej odpowiedzi ze stackoverflow ale nie jest ona w pełni miarodajna z dwóch powodów:
- Zakres danych jest relatywnie mały
- Odpowiedź jest stara
Z tych dwóch powodów postanowiłem przeprowadzić własne, bardzo podobne testy. Do tego celu użyłem zbioru danych IMDb – a dokładniej tych 3 tabel:
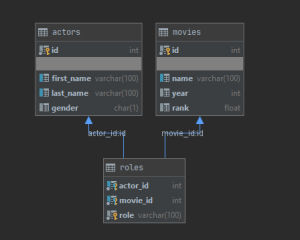
Wydajność testowałem na tabeli actors która posiada 817 718 rekordów a dodatkowo, żeby 'skomplikować’ nieco zapytanie, włączyłem jeszcze dociąganie danych z tabeli roles która u mnie posiada 1 467 257 wpisów (w bazie IMDb jest ich ponad 3 miliony ale nie starczyło mi cierpliwości żeby to wszystko importować).
Zapytanie wyciągające wszystkich aktorów, generowane przez hibernate’a prezentuje się następująco:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | Hibernate: select this_.id as id1_0_1_, this_.first_name as first_na2_0_1_, this_.gender as gender3_0_1_, this_.last_name as last_nam4_0_1_, roles2_.actor_id as actor_id2_2_3_, roles2_.role as role1_2_3_, roles2_.role as role1_2_0_, roles2_.actor_id as actor_id2_2_0_, roles2_.movie_id as movie_id3_2_0_ from actors this_ left outer join roles roles2_ on this_.id=roles2_.actor_id |
W ramach testu pobrałem całą kolekcję aktorów przy użyciu HibernateTemplate. Aby test był bardziej miarodajny, powtarzałem czynność kilka razy po 20-30 pobrań w ramach uruchomienia. Uśrednione wyniki:
Field-based access: 17720 ms.
Property-based access: 17914 ms.
Zbiór danych jest spory i jak widać różnica pomiędzy oboma strategiami dostępu nie jest widoczna. Ba! Nawet stwierdzę, że jej nie ma! W zależności od uruchomienia zdarzało się że to Property-based access był szybszy.
Co wybrać?
Chciałbym zaznaczyć bardzo wyraźnie, że jest to wyłącznie moje zdanie i może być tak, że wybór będzie zależał od wymagań Twojego projektu. Niemniej jednak – moim zdaniem – lepszym wyborem w większości sytuacji będzie Field-based access.
Oto 4 powody dlaczego:
- Czytelność kodu – wszystkie adnotacje masz zgrupowane razem przy definicji pól. Nie musisz przewijać po całej klasie aby zobaczyć czy aby na pewno dany atrybut posiada adnotację.
- Enkapsulacja danych – używając Field-based access nie musisz udostępniać wszystkich akcesorów – używasz tylko tych, które realnie potrzebujesz w aplikacji. W przeciwnym wypadku musisz udostępnić wszystko, tak aby framework mógł sobie poradzić z mapowaniem, pomimo, że sam, w kodzie biznesowym nie potrzebujesz dostępu do pól.
- Brak konieczności użycia adnotacji @Transient na metodach utility (np. addChild/removeChild).
- Uniknięcie bugów z niezainicjowalnymi encjami ładowanymi przez lazy-loading – odsyłam Cię do tego artykułu po więcej informacji.
Podsumowanie

Hibernate implementuje obie strategie dostępu do atrybutów encji zgodnie ze standardem JPA. To, którą opcję wybierzemy zależy od nas – developerów. Oczywiście zawsze na początku należy kierować się kontekstem w jakim się znajdujesz ale mając z tyłu głowy, że Field-based access jest bardziej przyjazny oraz pozwala uniknąć błędów.
A odpowiadając na pytanie z samego początku – czy potrzebujesz akcesorów, żeby móc zapisywać i odczytywać modele w Hibernate? Odpowiedź brzmi: nie. Hibernate poradzi sobie refleksją 🙂
Źródła:
- 2.5.12. Access strategies
- Access Strategies in JPA and Hibernate – Which is better, field or property access?
- Hibernate Annotations – Which is better, field or property access?
Za tydzień
Przejdziemy na płaszczyznę architektury oprogramowania i pogadamy o modelach domenowych. Anemic vs Rich Domain Model.
Ciekawe, też nie pamiętałem, że te getttery i settery nie są konieczne.
Jednak czy da radę z tego skorzystać w praktycznych zastosowaniach (poza małymi apkami) ?
Dobrą praktyką jest aby taką pobraną encję ASAP przemapować na tzw. DTO. I odwrotnie przy zmianach/dodawaniu.
Jeśli mapujemy to sami, to wtedy na pewno potrzebujemy getterów i setterów w encji. Gotowy tool mapcstruct też ich potrzebuje.
Ew tylko jeśli są jakieś inne toole do mapowania, które działają na refleksji to obędzie się bez getterów i setterów w encji.
Niestety encje hibernate nie mogą działać na Recordach (J 1.16+), które mają wbudowane gettery i settery.